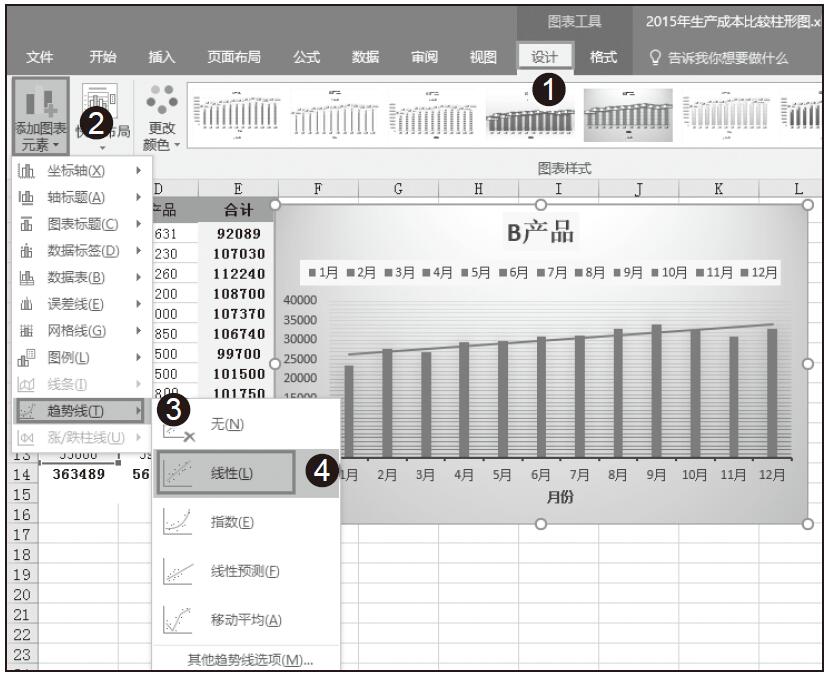
图1.2-1中第一个图表是真实的数据状态,在视觉上这8个柱形看起来差异非常小。第二个图表将Y轴最小刻度设在了60,第三个图表在0~70之间进行了折断处理,同一组数据绘制的8个柱形在第二、第三个图表上看起来差异非常明显。如果不认真读图(尤其第二个图表,将会导致图表反映的数据出现偏差),大脑通过视觉获取的就是错误信息。
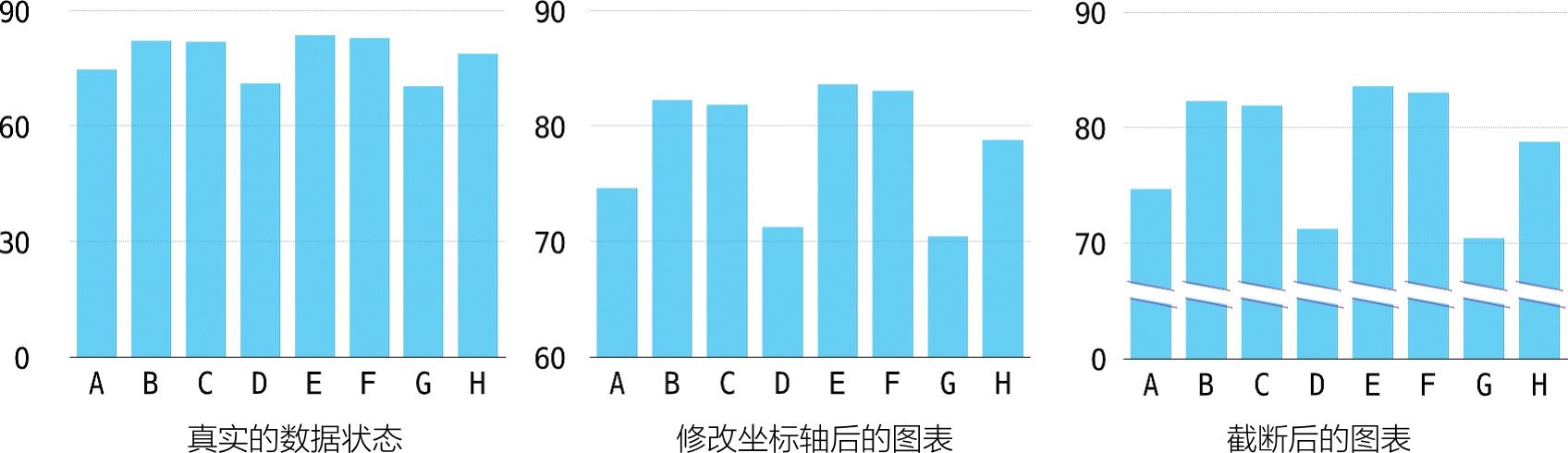
图1.2-1 同一组数据三种状态下的图表
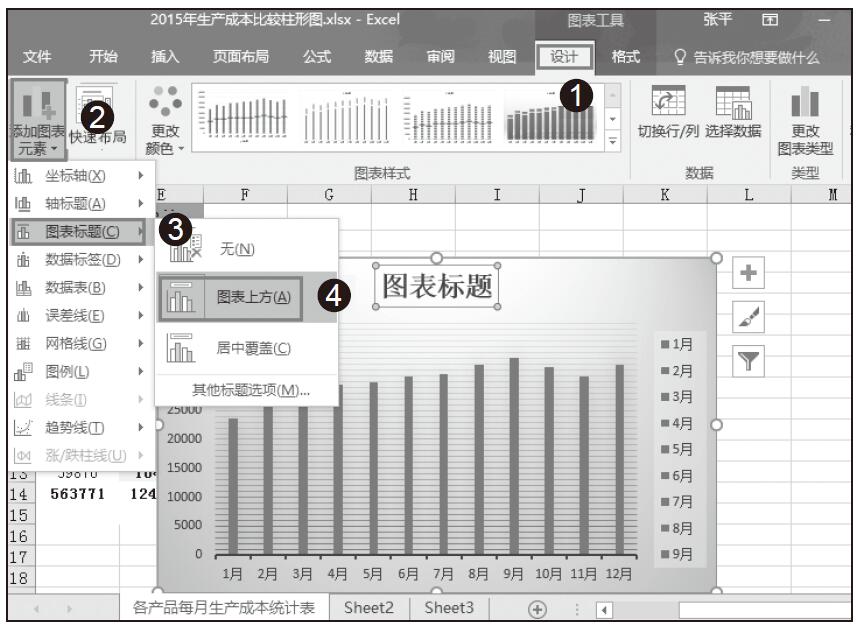
图1.2-2整个画面由于使用了积木,很有趣味性。但如果没有积木顶端的数据标识,读者根本无法直观获取到准确且有价值的数据。由于透视和单个积木高度的关系,这样的图表让人迷惑和难于理解,看过后留在大脑的仅仅是不同数量积木叠加并排列的图片,而非各类保险品种的比重信息。

图1.2-2 关于保险的调查
图1.2-3展示的图表形象直观,但详看之下却发现:数据截止位置到底是处于汽车品牌标志的顶部还是中间?这让人很困惑,不同的人会有不同的解读。汽车品牌标志位于柱形上部,模糊了柱形的准确截止位置,无法准确给出视觉参考基准,于是歧义就这样产生了。

图1.2-3 某汽车销售公司各品牌销售一览
■ Lie Factor畸变因子
“Lie Factor=Size of effect shown in graphic/Size of effect in data”
畸变因子=图表中有效表达的数据量/所有的有效数据量
即图形在表达数据诉求时的失真程度,这个评价系数越接近1,图表的失真度越少。图表本身不会产生谎言,造成图表“谎言”的原因很多,尤其当前大多数互联网及其专业杂志的图表制作人员多为平面设计出身,他们常常没有最基本的统计学知识,过于崇尚美学效果,使图表失真度被无限放大,制作出来的图表只能是徒具图表意味的美术广告作品。